Embodiment Agents¶
An Embodiment Agent is a virtual character that lives inside the simulation and guides the trainee through it. The trainee speaks to the character with their voice, and the character replies with a natural voice, on-screen subtitles, animations, and lip-syncing.
Each agent is grounded in your own material. Through a Retrieval Augmented Generation (RAG) pipeline, you upload the documents the agent should know — PDFs, Word files, or plain text — and the agent draws its answers from them. This lets you tailor an agent to a specific procedure, protocol, or curriculum without writing prompts by hand.
An Embodiment Agent in a simulation.¶
Speech-to-text and text-to-speech are powered by Microsoft Azure Speech, so the interaction feels conversational rather than menu-driven.
How an Agent is Created¶
Authors build agents in the ORamaVR Portal. The workflow is straightforward: sign in, upload the documents that form the agent’s knowledge base (its Library), then create an agent linked to one or more libraries. The Portal returns an Agent ID — a single string that gets pasted into the agent component inside Unity.
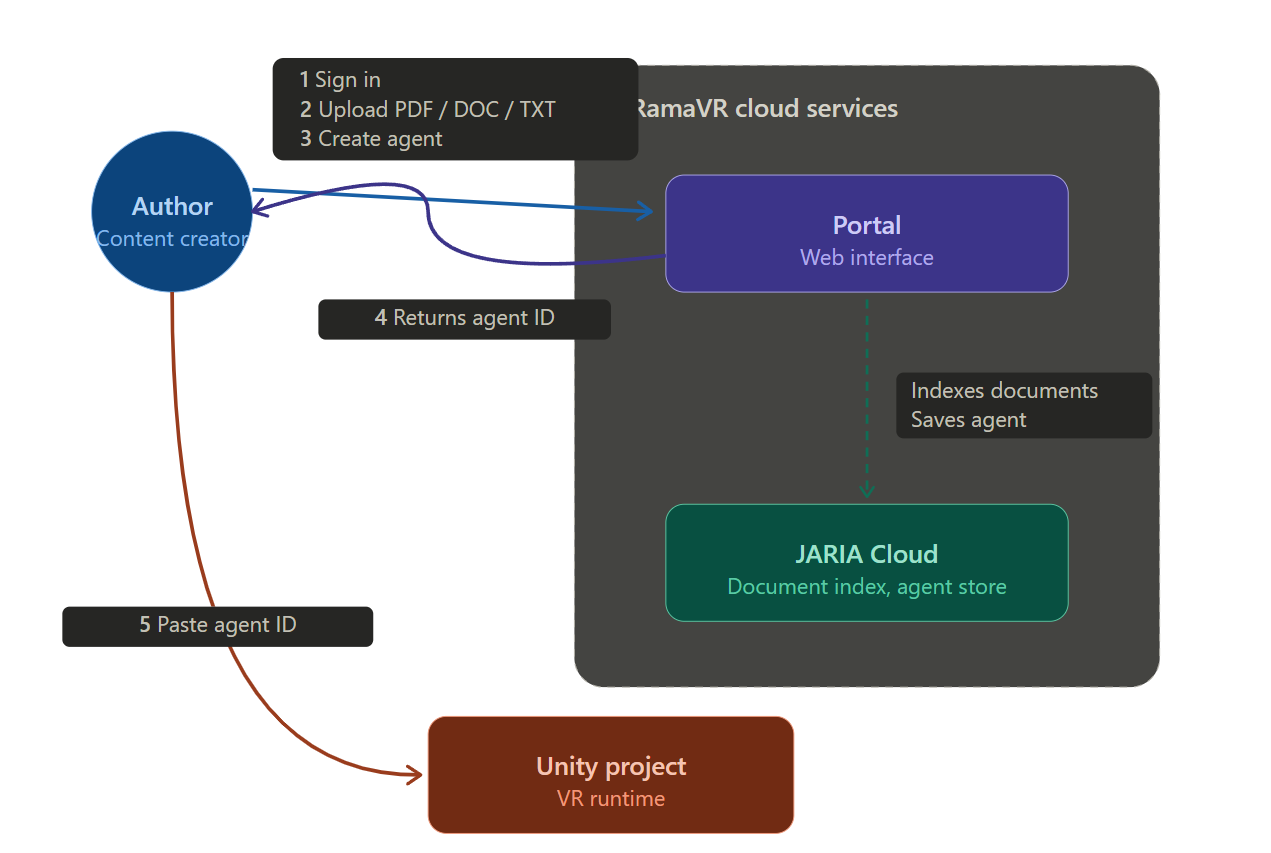
Creating an agent in the ORamaVR Portal.¶
For a step-by-step walkthrough of the Portal, see How to create an Agent in the Portal. For the Unity-side configuration, see How to create an Embodiment Agent.
How an Agent is Used¶
Once configured, the agent appears in the scene as a virtual character with an interact button. When the trainee presses interact and speaks, the agent transcribes the audio, asks the JARIA Cloud for a response, and replies with synthesised voice plus subtitles. The character can also follow the trainee with its gaze and animate while speaking, so the exchange feels in-person rather than transactional.
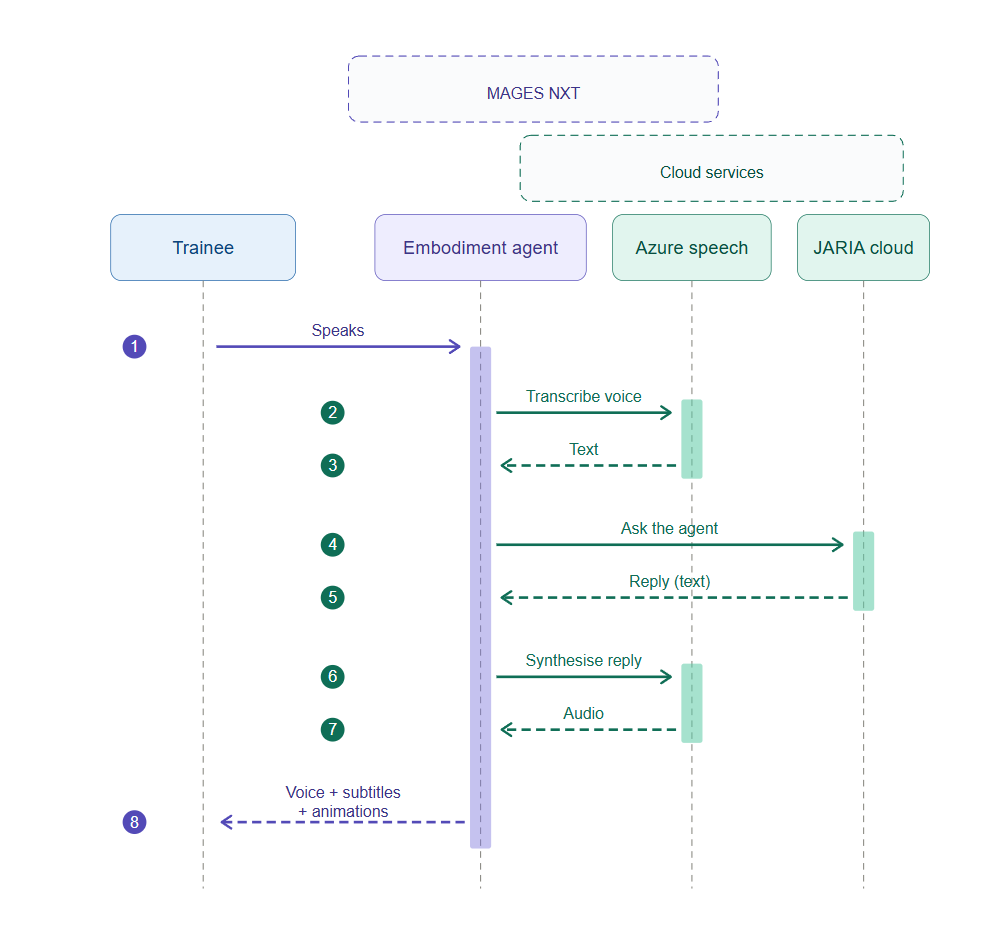
The voice loop between the trainee, the agent, and the cloud services.¶
Multiple agents can coexist in a single scene, and in cooperative sessions their voice and subtitles are synchronised across all participants — only one user can hold the interaction at a time. For the runtime setup, see How to setup an Embodiment Agent.